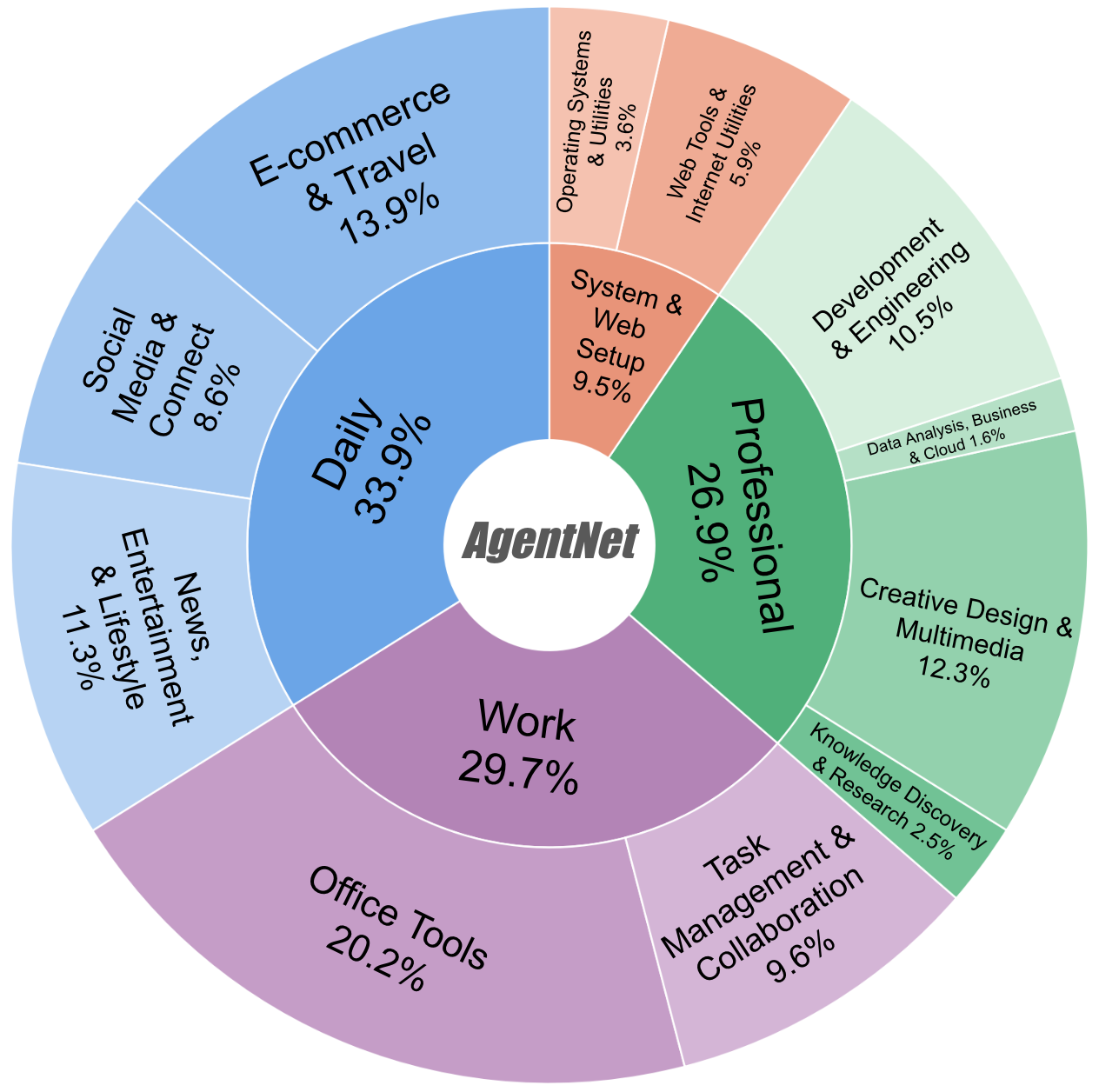

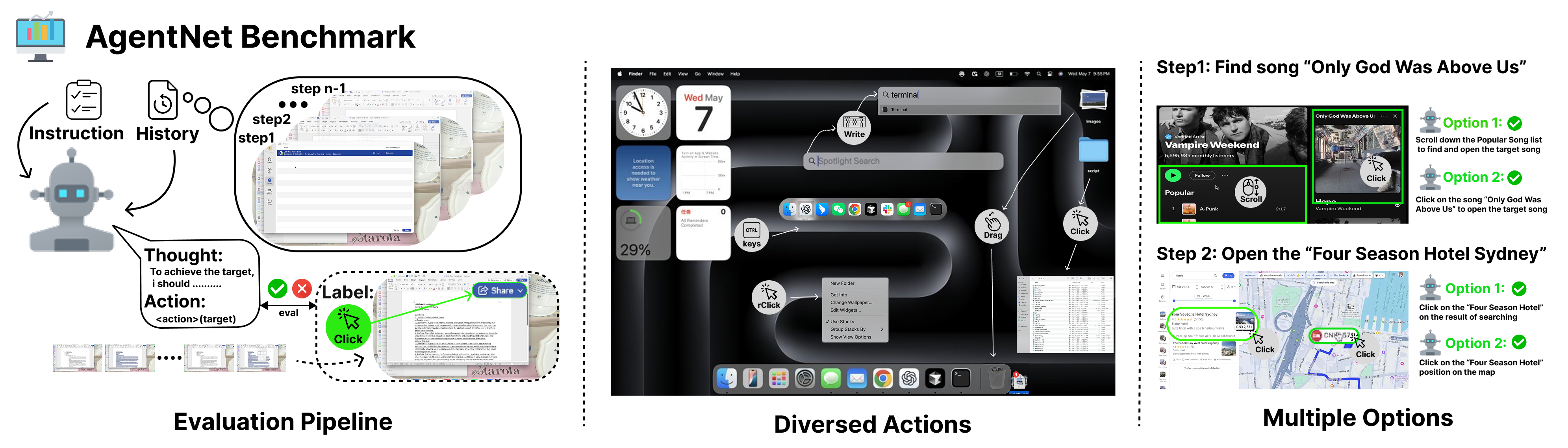
Analysis
Data Scaling and Test Time Scaling
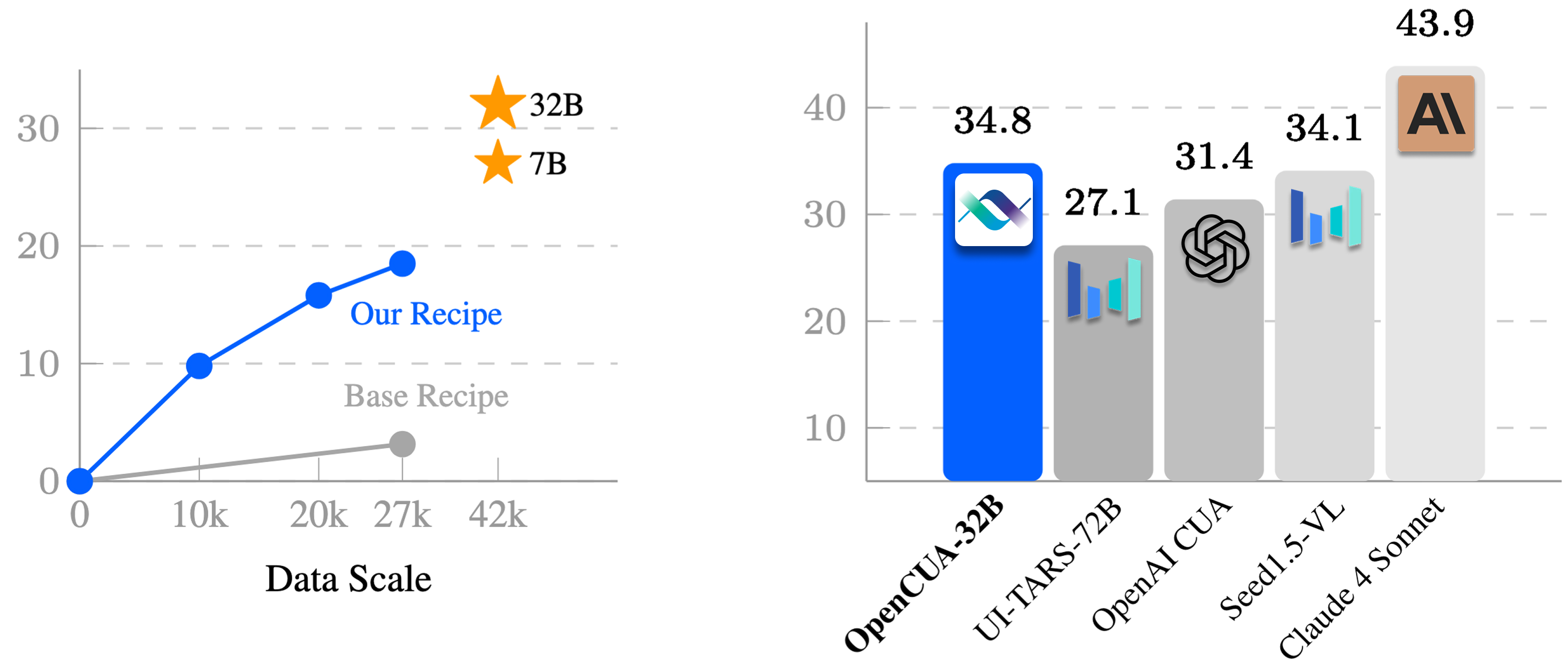
Our method enables performance to scale effectively with increased training data. The high Pass@N performance demonstrates OpenCUA-7B has great potencial of test time scaling.
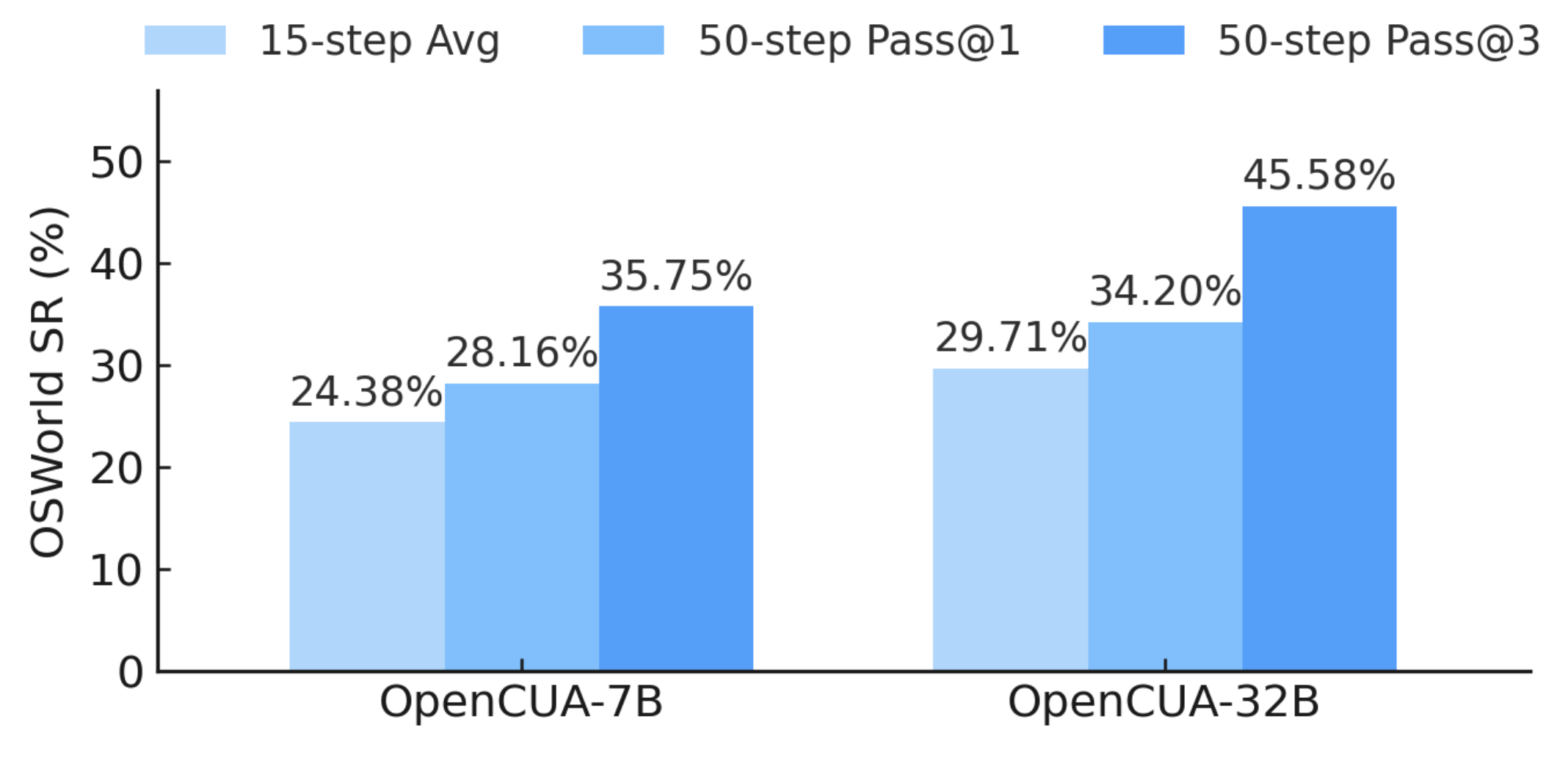
Test-time scale performance on OSWorld
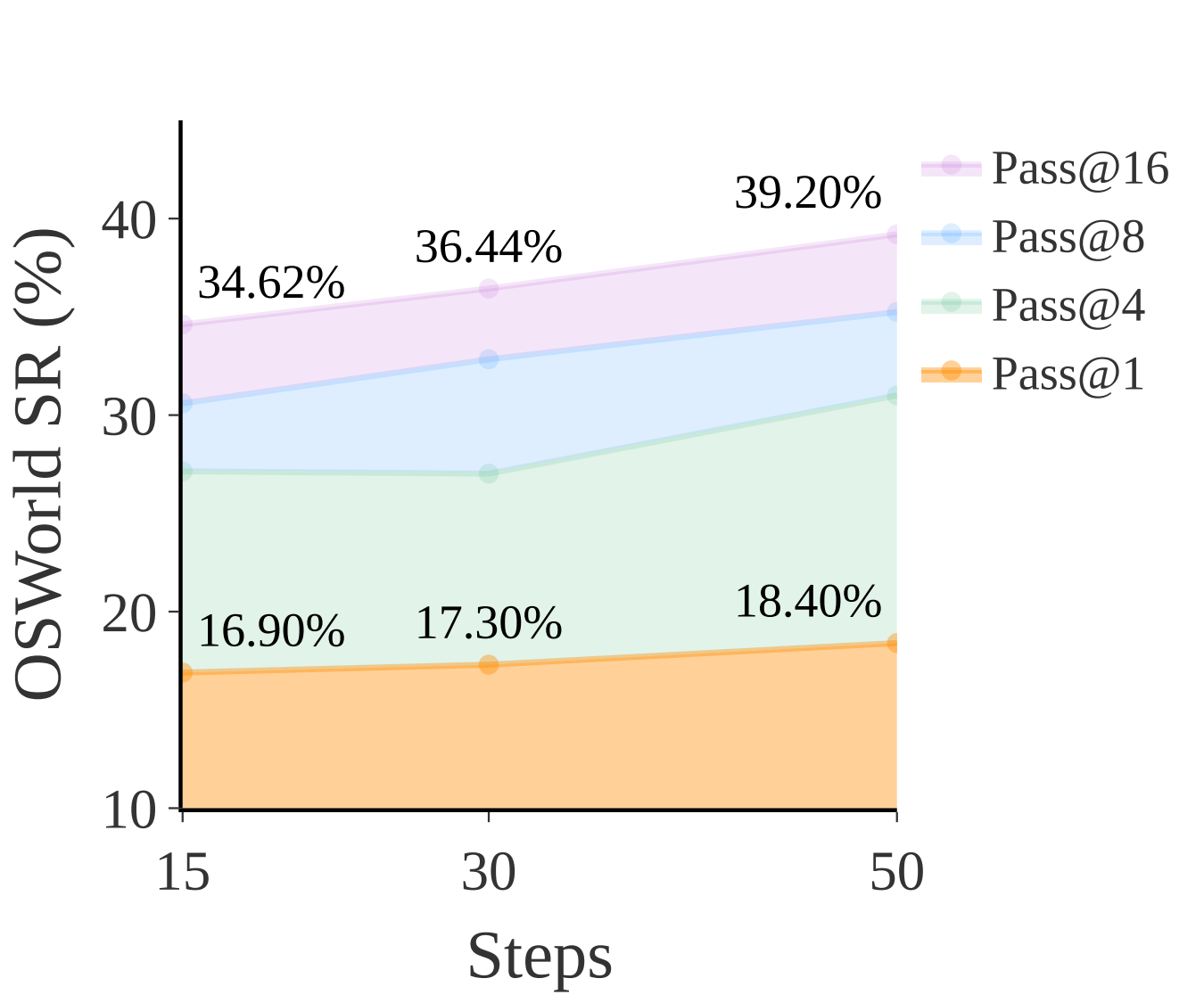
Pass@N curves (temperature = 0.1)
Domain transfer
Training Qwen2-VL ablations on Ubuntu-only or Win&Mac-only data still boosts OSWorld (Ubuntu), WindowsAgentArena (Windows), and AgentNetBench (Mac/Windows), proving cross-OS skills transfer instead of memorizing UI patterns.
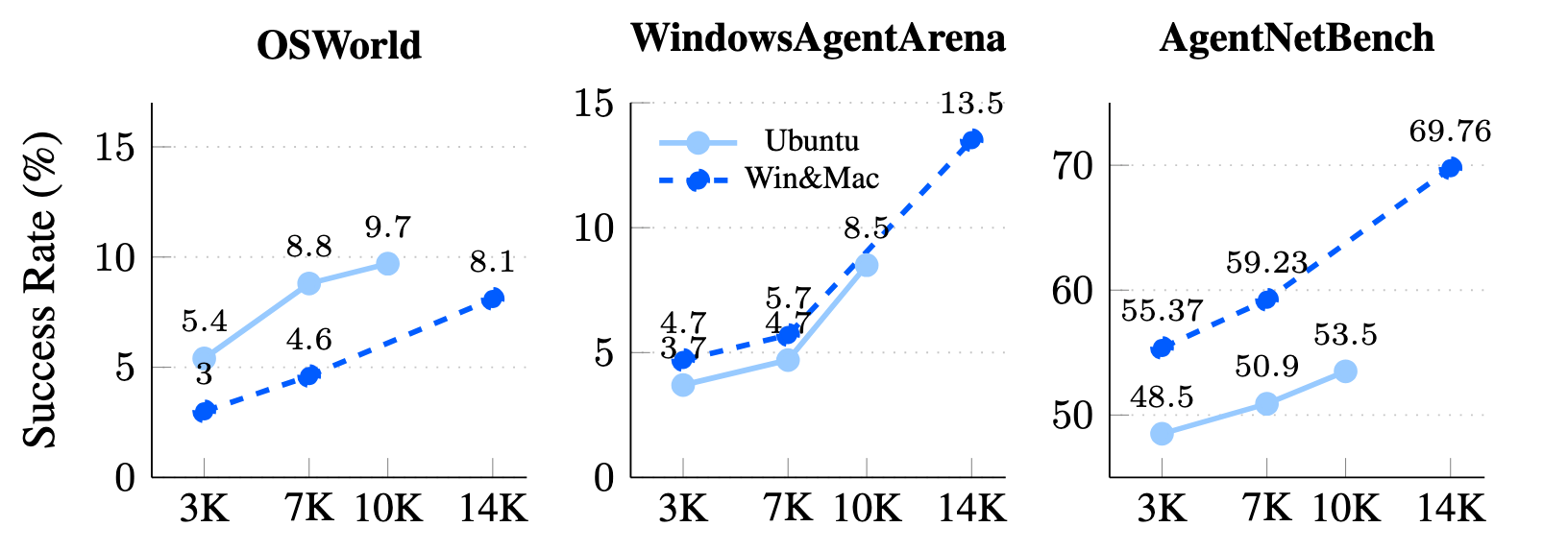
Training on Ubuntu vs. Win&Mac data benefits all benchmarks.